
随着超大规模预训练技术的快速发展,人们的关注重点已经不再局限于更大的模型规模,更加出色的模型效果正在不断刷新业界的认知和期望。
在过去,网易伏羲不断尝试从数据、算法、系统、应用等多个方面进行超大规模预训练技术的积累和探索,尝试构建了一个以政府支持为依托、集团内矩阵合作的联合开发模式,并在集团各个业务线的展开了联合实践。
本期我们邀请到了网易雷火伏羲大规模人工智能系统研制及基础算法专家,来和大家分享关于大规模模型在网易伏羲团队中的研发过程与应用成果,共同思考关于超大规模预训练技术应用的更多可能。
1. 大模型发展现状
整体来说,今年超大规模预训练技术依然保持了快速发展的势态。更大的模型规模不再是大家关注的重点,相应的图文生成的出色效果在不断刷新业界的认知和期望。比如OPENAI的DALL-E2,Google的Imagen、Parti以及黑马团队的MidJourny和 Stable Diffusion都有非常出色的表现。

应用层面开始大量涌现很有意思的尝试,比如生成哈利波特各个角色的原型、构建地球进化的过程、编著漫画作品等等。技术和应用的持续创新及宣传,使越来越多的人认识到了图文大模型的潜力和价值,让行业看到了预训练技术带来技术革新和广泛应用的可能性。
除了利用自然语言进行绘画、音乐、文字等相关方向创作及编辑的能力以外,自然语言及衍生知识的进一步利用也有了许多有价值的进展。OPENAI和微软合作训练的Codex,提供了一种联通自然语言及编程语言的能力,普通用户通过跟机器对话的方式就能实现代码编写。除此之外,通过进一步优化的自然语言模型,也能进行逻辑处理、表格制作等一系列脑力工作。OpenAI 目前已经基于GPT-3构建了数十种这种类型的API能力,并且保持了不断增加的趋势。

Codex: 用自然语言写游戏
以上的这一系列进展,都使得原来门槛较高的工作,可以通过人们最常用的交互方式去实现,降低了行业壁垒和实用门槛。
2. 伏羲大模型研发
2.1 初识图文模型
21年10月,伏羲超大规模预训练模型云平台项目正式成为浙江省重点研发计划-省尖兵支持的攻关项目,由此大规模预训练研发工作开始进入一个比较快发展的阶段。省科技厅为网易的大模型研发工作提供了较好的政策及资源支持,使得我们有机会尝试一些更有挑战性的工作。在攻坚任务等研发框架下,伏羲启动了包括图文、音乐、智能制造等相关方向的预训练能力积累,推动了一些非常有探索性的尝试。
比如,探索预训练模型结合强化学习、数字孪生,在智能制造领域的应用可能行;联合传媒、云音乐的同事一起进行图文多模态领域能力的积累及应用探索。目前多部门的联合共建取得了相当不错的业务反馈,帮助大模型方向完成了基础框架、数据积累和算法改进等方向的建设及补全工作。
多模态大模型的共建是去年自然语言大模型合作的衍生工作。 去年10月份以后,伏羲尝试对原有的自然语言大模型及推理引擎进行了开源。机缘巧合下我们与传媒同事取得了联系,并尝试联合共建大模型的相关技术及应用示范,也是在这个框架下,双方梳理了基于大模型技术的共同需求及探索计划,明确自然语言之后的图文理解是双方、乃至大多数兄弟团队的技术痛点。相关能力可以为许多检索、推荐业务提供核心的特征提取支持,在网易的业务场景中有广泛的需求和验证场景,同时也是图文生成能力的核心基础。
2.2 小试牛刀
最早一版的图文模型基于2亿对开源的图文数据及1500万业务脱敏数据进行训练,采用了类CLIP的结构和技术路线,行业脱敏数据很好地为项目组提供了业务参照和优化目标。
通过将模型能力替换到传媒已有的视频封面选定任务,项目组很快地对模型的效果和价值进行了验证。通过一线的业务实践有效地缩短了图文预训练模型的有效性验证过程、帮助项目组收集了算法效果及改进思路,在当时国内少有中文图文匹配开源或数据分享的情况下提供了一手信息。通过在几个周期的迭代和优化,第一阶段的工作在视频选定封面的业务当中得到了一定的效果验证。经过公司内、外部的测评团队的多次验证,该业务的核心算法的关键指标有了数个百分点的提升。
随后,网易云音乐的推荐团队着手将模型提取的特征引入到Mlog的短视频推荐任务,通过对用户观看内容的图文信息特征提取,补充之前推荐引擎中纯从用户角度建立的特征来源。这一阶段的工作并未对模型进行finetune,离线数据的验证接入大概用了一周左右的时间。很快,云音乐的同事发现图文预训练模型的引入对原有的业务有非常明显的帮助,离线验证中,hr@50和ndcg@50 均有大幅提升。
对于推荐业务来说,这个程度的提升是非常鼓舞人心的。随即在播客团队的同事协作下,初始版的图文模型被推送上线进行验证,特定业务模块线上的曝光量在两周内得到了超过200%的提升。大家都知道推荐领域的核心数据的提升其实是非常难的,往往很小的收益就需要付出大量的代价,甚至忙活很久还是负收益,因此这些业务数据的反馈让三方协作的同事都很开心。图文预训练技术得以快速验证,一方面是比较幸运,另外一方面是依托了云音乐非常完善的业务流程和基础设施,使得新的方法可以高效地得以验证。

初版模型集成到线上以后的曝光收益
2.3 再接再厉
第一版图文模型的研发和验证,在磨合三方团队的同时为后续的紧密合作打下了基础。通过定期的同步及分享,从数据、算法及应用层面不断地推进迭代和优化,很快在后面的过程中,我们训练出基于8亿图文对的4亿参数模型,同时尝试了多种模型结构组合和预训练方式。同时伏羲也与华为“悟空”团队建立了深入的合作关系,从数据、算法和系统方案上进行了协作和对齐。改进版的模型在效果上较初版又得到了较为明显的提升,基准测试也优于目前开源的悟空模型。

图文模型效果比对(i2t: image to text t2i: text to image R: recall)
模型下游应用方面,期间我们主要做了两件工作。
一方面,我们打通了一些受限数据的业务场景下的模型共建流程。网易云音乐作为一家独立上市的公司,对数据合规有非常高的要求,尤其对用户数据的使用有更加严格的审核标准,面对这项挑战,各部门系统平台侧的同事共同设计了一个模型动数据不动的去中心化的计算方案。基于杭研基础平台中心计算技术团队的支持,通过VK的标准化协议,联调各部门的集群调度权限,通过云原生技术将大模型的finetune任务调度至下游业务控制的计算集群内,基于可信的计算设施完成大模型的下游任务适配,最终通过分布式存储技术将脱敏后的任务模型存回模型托管中心。

基于vk架构的去中心化计算方案
另一方面,我们验证了基础模型对下游业务的提升效果。大多数的文献或者讨论都认为一个好的基础模型可以对下游任务的效果和适配效率有一定增益,但是这部分的信息在网易以往的工作中是缺乏验证的。所以在改进模型的应用过程中,研发组重点构建了没有基础模型和有基础模型进行效果对比。大家欣喜的发现,基于基础模型的finetune的模型效果较纯业务数据训练的模型效果存在非常明显的提升,两者img2text 和 text2img的HitRate@1差不多都是3倍的关系,上线后的模型效果也较之前的版本有了超过30%的提升。
通过以上两条路径的联合构建,通过云音乐的业务有效验证了大模型从联合研制到定制优化再到业务赋能的完整路径。目前基于图文内容理解的特征提取已成为云音乐冷启动的重要方法,相关能力也正被集成至云音乐多模态团队构建的联合推荐引擎当中。
2.4 基础系统建设
系统方面,我们从算力调度和推理引擎等几个角度进行了持续优化。通过打通伏羲私有云和国家超算的算力资源,实现了训练资源的低价引入和可控使用。推理引擎方面,在原有的EET项目基础上持续量化及定制算子开发的工作,不仅可以支持百亿级模型的量化及单卡推理,同时也支持了更多多模态场景下的经典模型,比如VIT、CLIP等。我们还对基于transformer框架的text encoder和image encoder进行了推理优化,大幅提升了推理速度,满足了线上的高并发需求,并且降低了部署资源的损耗。

3. 大模型在雷火业务场景的落地
3.1 智能标签
随着模型能力、基础系统的不断完善,我们也开始尝试在雷火的业务场景上进行图文理解能力的落地。MUSE是雷火研发的美术资源及协作管理系统,在MUSE上,我们尝试通过图文理解模型解决已有的美术资产管理的问题。
一方面对大量的已有素材打标,另外一方面为MUSE的用户提供更加智能的内容检索。
对已有美术资产的打标分类在没有大规模预训练模型介入前是一个比较难解决的问题。主要的挑战来自业务的冷启动,同样这样的问题也会在很多其他业务当中出现。具体来说,MUSE有大量原始数据,对这些数据进行标定或分类需要有很强的背景知识,同时对数据资产的安全性也有很高要求。这两方面的制约使得数据早期的标注有一个非常高的门槛,以至于高到无法有效地推进业务的落地。
通过图文预训练模型在互联网数据上学到的先验知识,结合从专业领域网站抽取的几十万标签,项目组很快便完成了数十万原始资产的分类打标。经过算法的适配及工程优化,目前多模态共建项目为MUSE提供了高效的打标服务,系统根据用户上传的资源进行智能打标,平均每张图片的打标时间在几百毫秒左右,大大减少了标注的耗时。这些标签的准确度相对较高,解决了80%以上的应用问题,使得业务有信心通过后期部分专员的介入解决剩下的问题,从而整体解决原始美术资产缺少分类和标签的问题。

MUSE平台AI自动打标

MUSE平台AI自动打标
3.2 联合检索
另一方面,伏羲和MUSE的同事一起利用预训练模型的能力,针对大量的外部数据进行了特征提取及建立索引。模型能力的引入,使得我们的引擎相比市面上其他友商提供的专业引擎具备更高的图文理解能力。相比图文预训练技术,大多数主流的搜索引擎主要基于分词和组合来做,这种技术路线对于一些不太常见的、非规则性的表述没有一个特别好的理解效果。比如很早以前的“五彩斑斓的黑”,直到这种表述变成主流说法以后搜索引擎才有比较好的检索效果,然而这种非规则的,脑洞大开的表述往往在游戏研发场景中又是特别常见的,比如艺设的同事想搜“古风坦克”,在友商的搜索当中都有没有特别好的效果。

古风坦克搜索效果比较
在通用搜索引擎当中只能搜出古风或者坦克,没有两个词汇组合以后的搜索结果,而在垂类网站的搜索结果中,则几乎搜不到东西。但是通过图文预训练模型的理解和索引则可以很好地检索到古风坦克这种很小众的创作内容,这些内容很可能已经存在于商业化图片检索引擎的数据库中,只是他们的算法无法理解这些早已被艺术家创作出来的内容。
同样,赛博朋克自行车也是一样的效果。相信基于图文预训练模型的智能搜索可以帮助美术的同事更容易地获得灵感,降低研发过程中的沟通障碍。

伏羲智能搜索:赛博朋克自行车
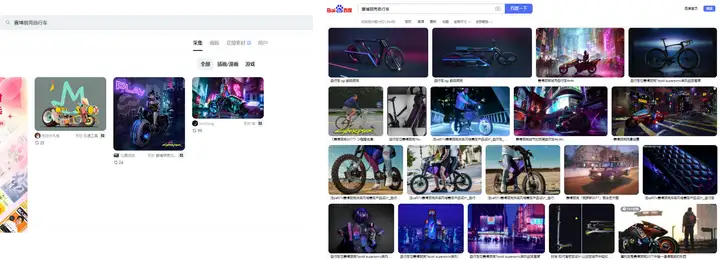
花瓣及百度对比:赛博朋克自行车
4. 总结和展望
目前网易自研的图文理解预训练模型取得了一定进展,也希望这些基础能力可以更好的赋能到公司的各项业务,除此之外,我们也在正在努力孵化基于中文的图文生成、智能抓取等预训练能力研发工作。
期待在不远的将来,在超大规模预训练模型技术领域可以有更多具备网易特色的工作,也期待本次分享能给大家在更广阔的领域与业务场景中应用提供一些可能的思路,谢谢!