
近日,网易伏羲实验室将强化学习引入游戏AI开发的新成果。
“Applying Reinforcement Learning to Develop Game AI in NetEase Games”成功入选了游戏开发者大会 (GDC) 2020 Core!
 |
此次提案是网易伏羲实验室自主开发、独立投递的成果,是国内首个入主GDC核心的游戏研发方向提案,体现了网易伏羲实验室一流的游戏AI开发能力。
那么,到底是什么样的技术和运用成果获得了世界顶级的游戏开发者盛会抛出的橄榄枝?今天这篇文章将从游戏AI的发展现状讲起,详细说明伏羲实验室近来在强化学习游戏AI商用化上的探索和突破。
进退之间:游戏AI开发的瓶颈
实际场景中,人工智能在商业落地方面还有很长的路要走,面对人类世界诸多繁杂问题的算法系统始终达不到足够量级。虽然,世界一流的顶级公司基于StarCraft 2(星际争霸2)和Dota 2这两款游戏开发的游戏AI——DeepMind和OpenAI已达到人类顶级玩家的水平。然而,作为科研领域的前沿探索,两款AI更像是利用游戏完美的训练环境进行AI研究,投入了巨大的训练资源;花费了大量的训练时间;且在与人类对抗的时候添加诸多限制。也就是说,现存游戏AI并不完全适用于商业游戏内用户导向的内容开发,国际顶尖的游戏AI水准并无法成为一个商用标准。
 |
|
DeepMind星际争霸AI登上Nature |
需要明确的是,商业游戏AI的落地与开发应该拥有更高的投入与产出比。同时,为了让玩家有更好的游戏体验,AI的胜率不是唯一的考核标准,更重要的是能提供行为多样、充满智慧且有趣的AI。出于这些考量,商业游戏AI开发的领域还处于沉寂期。
工具为赢:强化学习助力游戏AI破冰之旅
网易伏羲实验室作为网易游戏的研发部门,近年来在AI领域不断发力,已在MOBA,MMORPG,SPG等游戏类型中积累了较为丰富的商业游戏转化经验,为商业、技术提供了一体化的有力保障。
而此次AI强化,背靠实验室深厚的人工智能背景,运用强化学习等细分领域,聚焦于在网易游戏实操中强化学习开发游戏AI的具体运用。下面我们将主要介绍在AI开发过程中遇到的问题,尝试过的解决方案以及最终的效果。
基于网易游戏的AI开发需求,伏羲实验室发现——与传统AI方法(有限状态机、行为树)相比,强化学习AI有其特有优势,主要表现在AI行为的合理性、复杂性以及多样性上。在《逆水寒》流派竞武场景中,最高难度AI不仅在技术上超过了顶尖人类选手,而且其合理的打法得到了游戏制作团队的高度认可。
 |
|
AI完美克制玩家,以《逆水寒》流派竞武为例 |
而在潮人篮球3v3场景中,游戏AI不仅学会了基本的突破,传球和投篮等行为,更学习出了许多高级配合——挡拆,协防和突分等。
 |
|
潮人篮球3v3场景 |
当然,这个新技术也有一定局限,初期接入成本较高,迭代周期长,训练效果不可控等问题。为克服这些困难,实验室又进一步开发了一套训练工具,主体包含前端流程图和后端自研算法框架,总结了一系列解决方案并且形成了一整套开发流程规范,极大地提升了开发效率。
 |
|
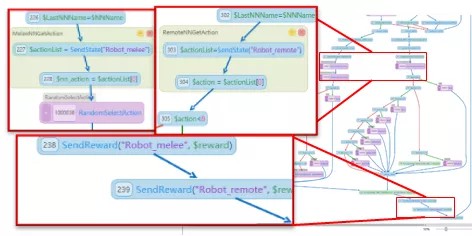
网易游戏前端流程图 |
上图为网易实际游戏中的一个前端流程图,该流程图除了定义了一些基础行为以外,在一些关键场景中引入了强化学习,图中放大的区域为与强化学习相关的两种节点——SendState和SendReward。工具简化了游戏接入过程,采用可视化编程方案并提供在线调试功能。该工具支持逻辑规则与强化学习混合编程,能灵活应对复杂场景需求。
 |
|
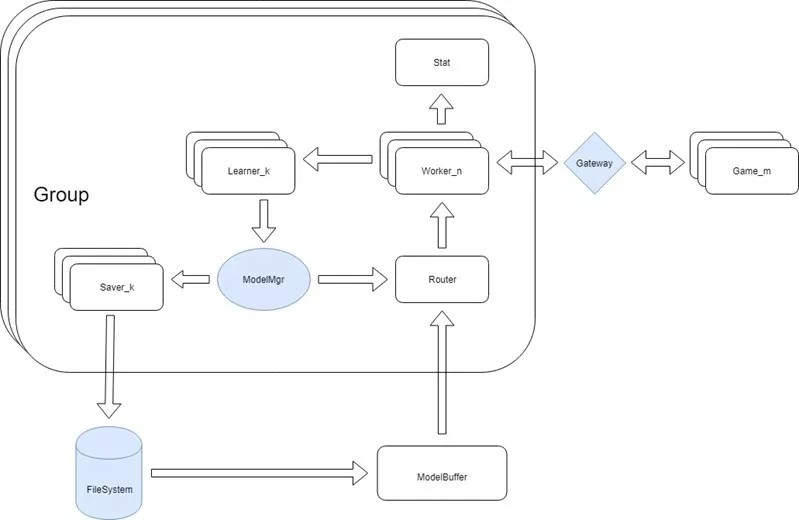
RLEase的框架示意图 |
后端算法框架RLEase针对游戏AI场景做了许多优化,不仅支持多种主流算法和游戏类型,而且针对强化学习算法特点配备了标准的API接口,提供了分层强化学习并支持分布式训练、Self-Play、风格多样化、难度控制等高级特性,对于使用流程图工具的游戏可以快速接入RLEase训练。
针对网易游戏中实际问题的几种解决方案
AI开发过程中,训练资源需求大、限制性强、接入成本较高,迭代周期长,训练效果不可控皆为世界范围内的难题,实验室立足于实际游戏运营中的产品需求进行技术支持,提供了几种解决方法,并且在具体游戏情景中得到初步运用成果。
下面给予几个局部升级以说明:
1.降低训练资源要求以减少游戏AI制作成本,提高投入产出比
针对创生物或多智能体场景使用更加灵活的建模方案,减少因图像输入对硬件资源的高需求。一个鲜明的例子是——《逆水寒》中龙吟职业的气剑技能,在AI开发中创新的使用雷达状态表示,用向量表示了不定数目、不定位置的气剑信息,从而避免了在训练时引入卷积层,降低了对GPU的需求。
2.降低大场景下的训练难度,巧用课程学习方法
实际游戏情景中,大地图中移动相比于战斗过程更加难以训练,此次开发采取了渐进式的课程学习方法,让AI先从近距离的战斗开始训练,随着训练进行慢慢拉远双方距离,最终使得AI学会更高层的策略——追踪、逃跑等。
3.全面匹配各个水平段位玩家,提升游戏体验
使用多种行为参数控制生成各种难度的AI,并利用Trueskill或ELO技术建立统一评价体系。对不同水平的玩家匹配合适难度的AI是游戏中的一个基本需求,为了控制和评价AI难度,实验室引入了参数控制机制(如下图),并且使用ELO一次性地产生各种参数对应的不同难度的AI,不仅减少了策划挑选AI的过程,而且提供了客观的难度评价标准。
 |
|
难度控制迭代示意图 |
4.让AI更像人,推进AI风格化
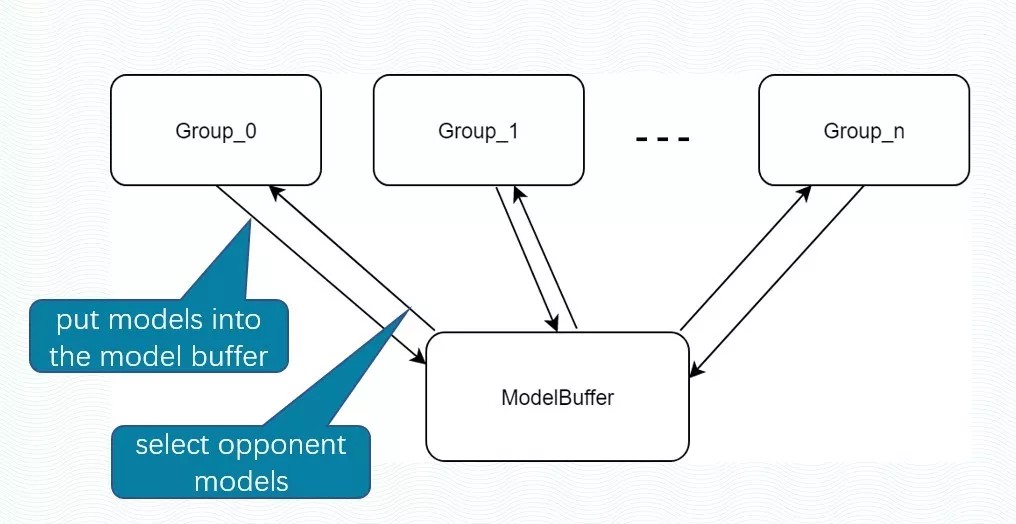
真实玩家的打法往往很多样,AI为了应对各种风格的对手,必须让训练对手更加多样化。实验室利用多种子多组奖励参数混合训练,同时生成多种行为风格的AI。虽然使用self-play训练方法在一定程度上能产生行为多样性的AI,但是整体上仍然容易陷入到一些局部行为中。为了克服这个问题,后端算法框架引入了多种奖励参数同时训练。
 |
|
多风格混合训练示意图 |
不同的奖励参数意味着AI有不同的目标(偏激进、偏保守等类),而主训练的Agent将在训练过程中遇到这些不同目标的AI,并努力去打败它们,从而减少上线之后AI无法适应玩家多样化打法的风险。
5.使用分层强化学习技术简化建模,提高复杂场景下的训练效率
在《潮人篮球》实际开发中,训练拥有高级行为的AI非常困难,需要大量的训练以及精细的奖惩设计。为解决这个问题,团队最终采用了分层强化学习方法,让上层网络决策宏观策略(如防守或挡拆),下层网络则在上层网络的指引下学习具体的操作,大大降低训练难度。
成果与展望
目前,伏羲实验室开发的强化学习AI已经为包括《逆水寒》、《倩女幽魂手游》、《流星蝴蝶剑》、《潮人篮球》等多款游戏提供了线上服务。根据项目组数据,单在《逆水寒》流派竞武玩法中,AI服务访问峰值就达到了8000+每秒,平均每天的请求量在7000万以上。
此外,强化学习AI在测评过程中的行为多样性、最高难度等指标上都超过了原先的行为树AI,是对原有游戏AI的巨大升级。
 |
|
《逆水寒》 |
另根据强化学习AI上线后的用户数据调研,社区内对游戏AI升级的讨论热度不减,“以为在和真人对战”、“同个等级的打不过”成为多数玩家的一致观点,并反馈新版本AI在打法和技能combo的使用上不仅仅合理与流畅,也更像真实玩家会选择的操作,甚至建议新手玩家学习AI打法。可以说,《逆水寒》的流派竞武场景不仅仅是网易游戏内部AI的巨大升级,更成为国内少有的超强AI实战场景。
 |
|
《逆水寒》用户社区真实评价 |
同时,目前AI上限被大幅提高,为游戏策划更进一步丰富游戏内玩法提供了技术支持。在具体运用上,流派竞武情景中就增加了强化武痴和武痴培养两个新玩法,针对不同玩家提供了更合适的匹配模式,较大地提升了游戏的可玩性。百闻不如一见,游戏AI如何见招拆招,制霸人类玩家,请看具体视频。
网易伏羲实验室的游戏AI为业界提供了——一种新的商业游戏AI制作方式,一整套配合开发的新工具,总结并制定了一整套开发规范。相比于传统方法,不仅提供了更高质量的游戏AI能力,简化了新技术接入门槛,更解决了一系列强化学习AI迭代过程中的常见问题,在三个切入点上立足商用,确保商用,助力大规模商用。
随着AI对环境探索能力的增强,并且不断更新迭代现有模型的机器学习算法,未来的游戏玩法将会发生巨大的变化,玩家将能够得到无限接近于现实生活的游戏体验,从而更沉浸于游戏内容本身,或许美剧《西部世界》中的游戏构想对每个人而言并不只是虚妄。
未来,网易伏羲实验室将会继续深耕AI领域,拓展技术能力,为更多游戏提供AI支持,助力行业发展,请拭目以待吧!
 |